
Text-generating AI is one thing. But AI models that understand images as well as text can unlock powerful new applications.
Take, for example, Twelve Labs. The San Francisco-based startup trains AI models to — as co-founder and CEO Jae Lee puts it — “solve complex video-language alignment problems.”
“Twelve Labs was founded … to create an infrastructure for multimodal video understanding, with the first endeavor being semantic search — or ‘CTRL+F for videos,’” Lee told TechCrunch in an email interview. “The vision of Twelve Labs is to help developers build programs that can see, listen and understand the world as we do.”
Twelve Labs’ models attempt to map natural language to what’s happening inside a video, including actions, objects and background sounds, allowing developers to create apps that that can search through videos, classify scenes and extract topics from within those videos, automatically summarize and split video clips into chapters, and more.
Lee says that Twelve Labs’ technology can drive things like ad insertion and content moderation — for instance, figuring out which videos showing knives are violent versus instructional. It can also be used for media analytics, Lee added, and to automatically generate highlight reels — or blog post headlines and tags — from videos.
I asked Lee about the potential for bias in these models, given that it’s well-established science that models amplify the biases in the data on which they’re trained. For example, training a video understanding model on mostly clips of local news — which often spends a lot of time covering crime in a sensationalized, racialized way — could cause the model to learn racist as well as sexist patterns.
Lee says that Twelve Labs strives to meet internal bias and “fairness” metrics for its models before releasing them, and that the company plans to release model-ethics-related benchmarks and data sets in the future. But he had nothing to share beyond that.
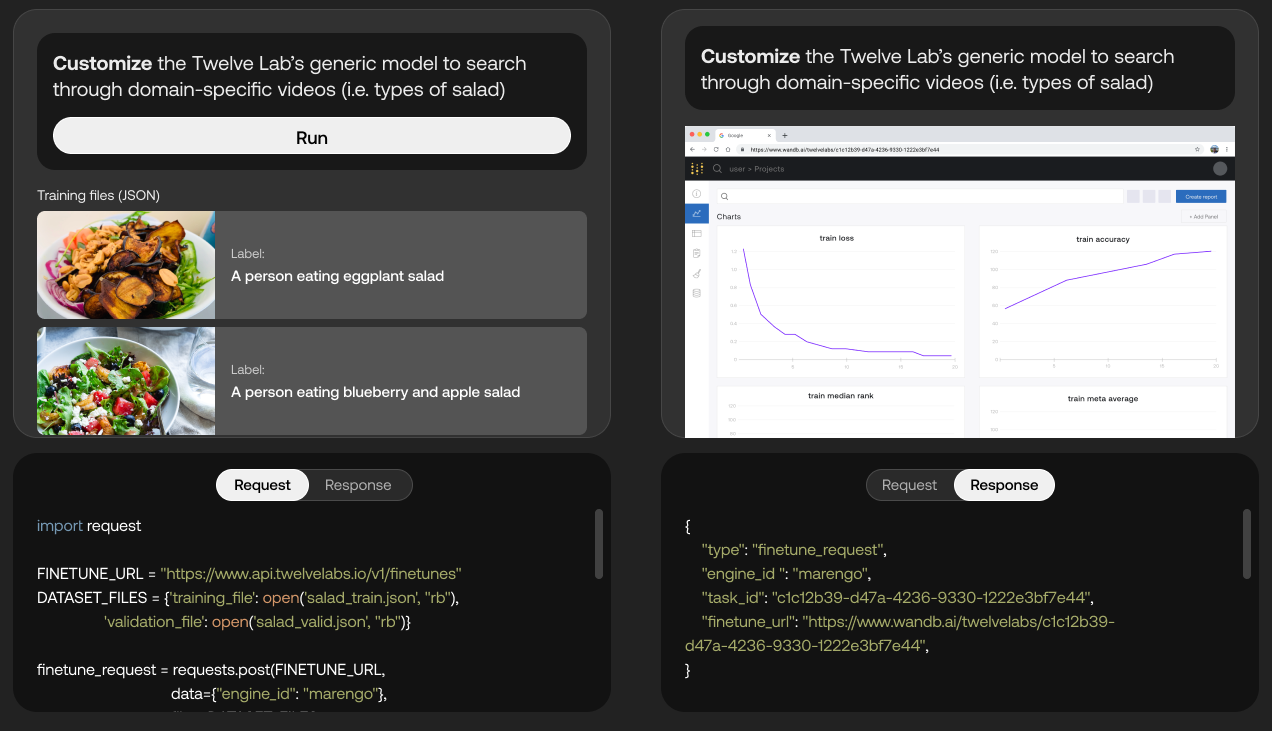
Mockup of API for fine tuning the model to work better with salad-related content.
“In terms of how our product is different from large language models [like ChatGPT], ours is specifically trained and built to process and understand video, holistically integrating visual, audio and speech components within videos,” Lee said. “We have really pushed the technical limits of what is possible for video understanding.”
Google is developing a similar multimodal model for video understanding called MUM, which the company’s using to power video recommendations across Google Search and YouTube. Beyond MUM, Google — as well as Microsoft and Amazon — offer API-level, AI-powered services that recognize objects, places and actions in videos and extract rich metadata at the frame level.
But Lee argues that Twelve Labs is differentiated both by the quality of its models and the platform’s fine-tuning features, which allow customers to automet the platform’s models with their own data for “domain-specific” video analysis.
On the model front, Twelve Labs is today unveiling Pegasus-1, a new multimodal model that understands a range of prompts related to whole-video analysis. For example, Pegasus-1 can be prompted to generate a long, descriptive report about a video or just a few highlights with timestamps.
“Enterprise organizations recognize the potential of leveraging their vast video data for new business opportunities … However, the limited and simplistic capabilities of conventional video AI models often fall short of catering to the intricate understanding required for most business use cases,” Lee said. “Leveraging powerful multimodal video understanding foundation models, enterprise organizations can attain human-level video comprehension without manual analysis.”
Since launching in private beta in early May, Twelve Labs’ user base has grown to 17,000 developers, Lee claims. And the company’s now working with a number of companies — it’s unclear how many; Lee wouldn’t say — across industries including sports, media and entertainment, e-learning and security, including the NFL.
Twelve Labs is also continuing to raise money — and important part of any startup business. Today, the company announced that it closed a $10 million strategic funding round from Nvidia, Intel and Samsung Next, bringing its total raised to $27 million.
“This new investment is all about strategic partners that can accelerate our company in research (compute), product and distribution,” Lee said. “It’s fuel for ongoing innovation, based on our lab’s research, in the field of video understanding so that we can continue to bring the most powerful models to customers, whatever their use cases may be … We’re moving the industry forward in ways that free companies up to do incredible things.”





